
lab7#
Please use this lab as an opportunity to review the course material and prepare yourself for hw7. Sample responses to the lab questions are provided below.
global repo https://github.com/jhustata/basic/raw/main/
Start Stata, open your do-file editor, write the header, and load
transplants.dta.
use "${repo}transplants", clear
Get a 10% random sample of the dataset. Specifically, follow these steps. (1) Set a seed number. (2) Generate a variable that includes a random number between 0 and 1 following a uniform distribution. (3) Sort by the random variable. (4) Keep the first 10% observations and drop the rest. (5) Drop the random variable.
Clear and reload
transplants.dta.
use "${repo}transplants", clear
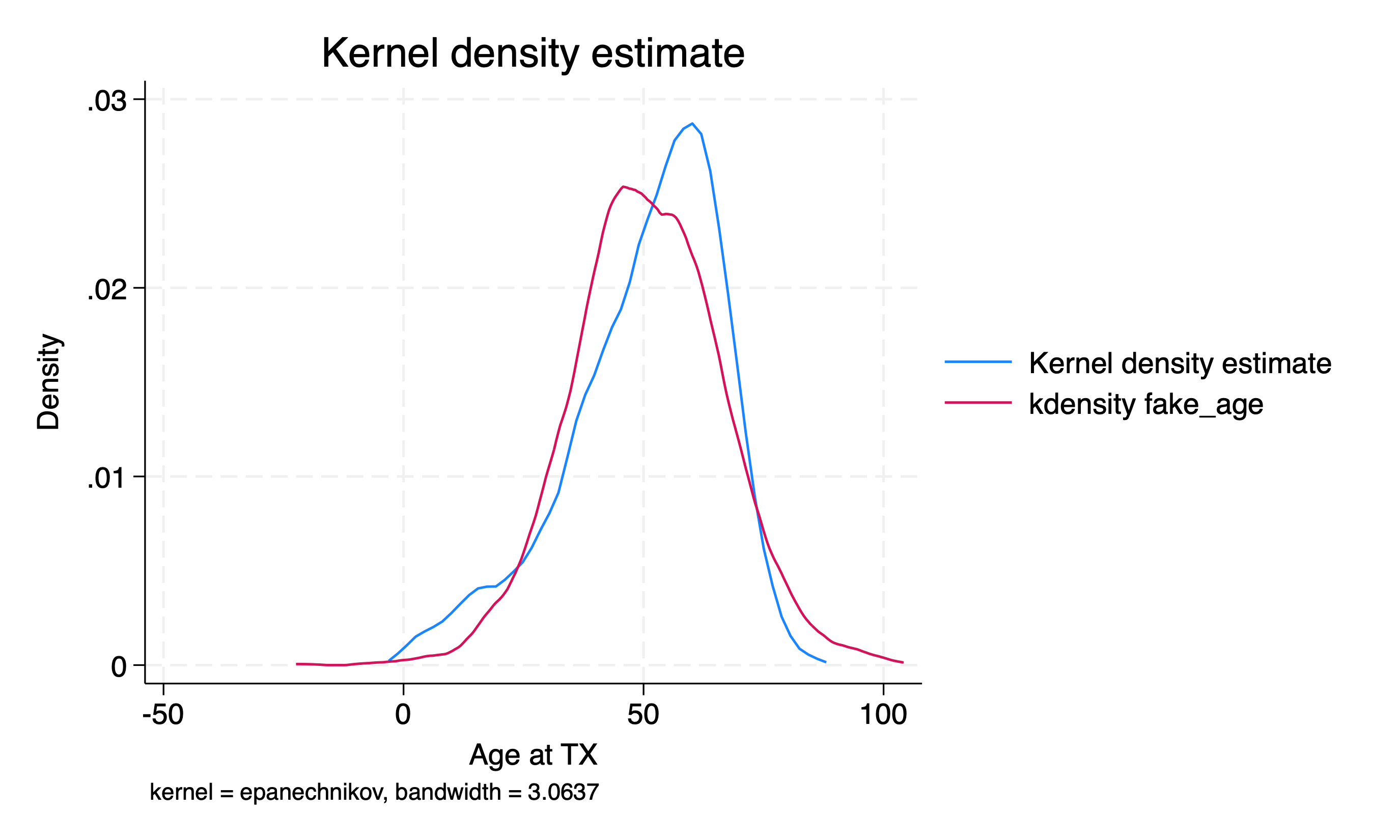
Generate a variable called
fake_agewhich is a normally distributed random variable with mean and standard deviation equal to the mean and standard deviation of the actual age variable.
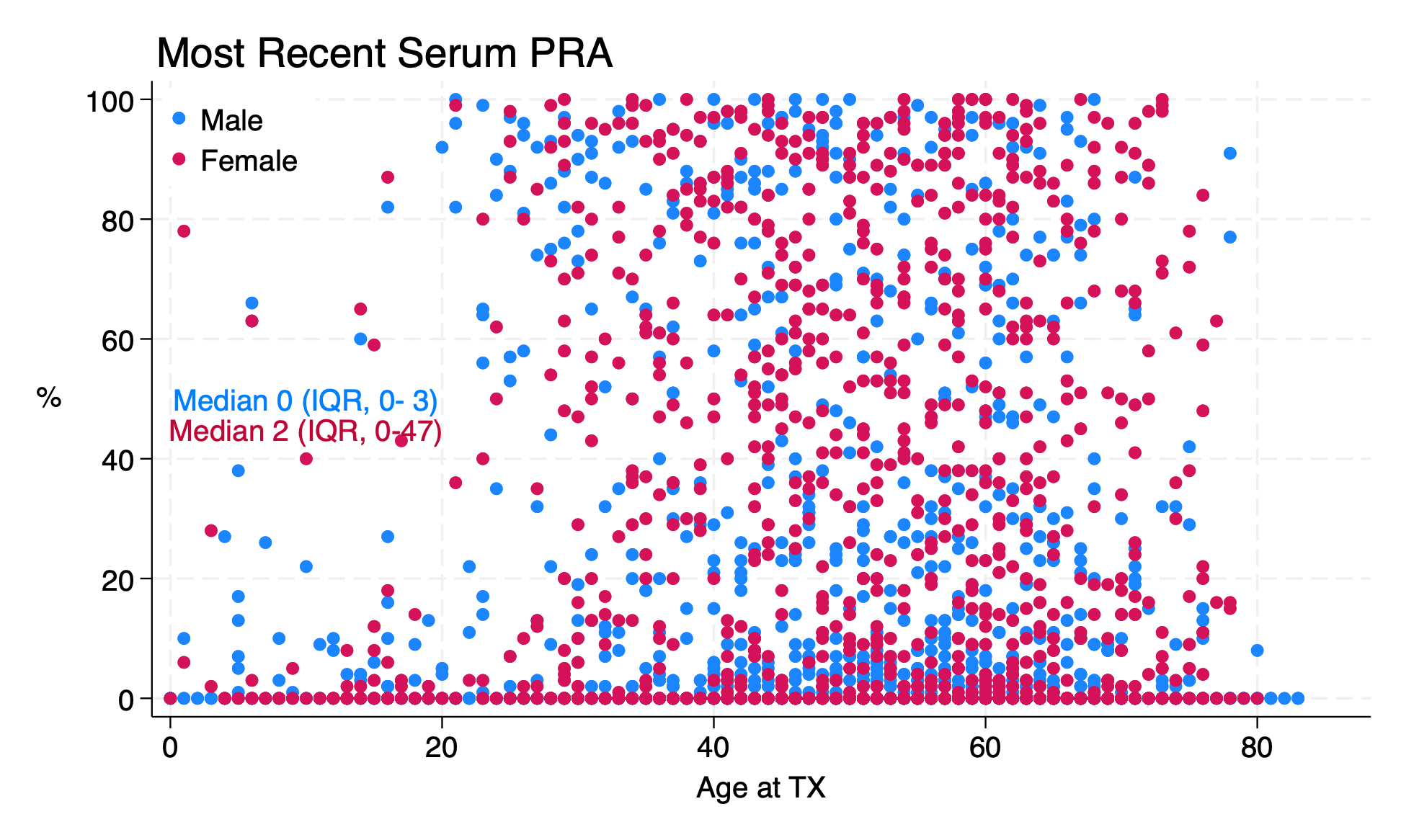
Make a scatter plot of peak PRA by age in transplant recipients. Does it look like there’s a relationship between peak PRA and age, and if so, what is the relationship?
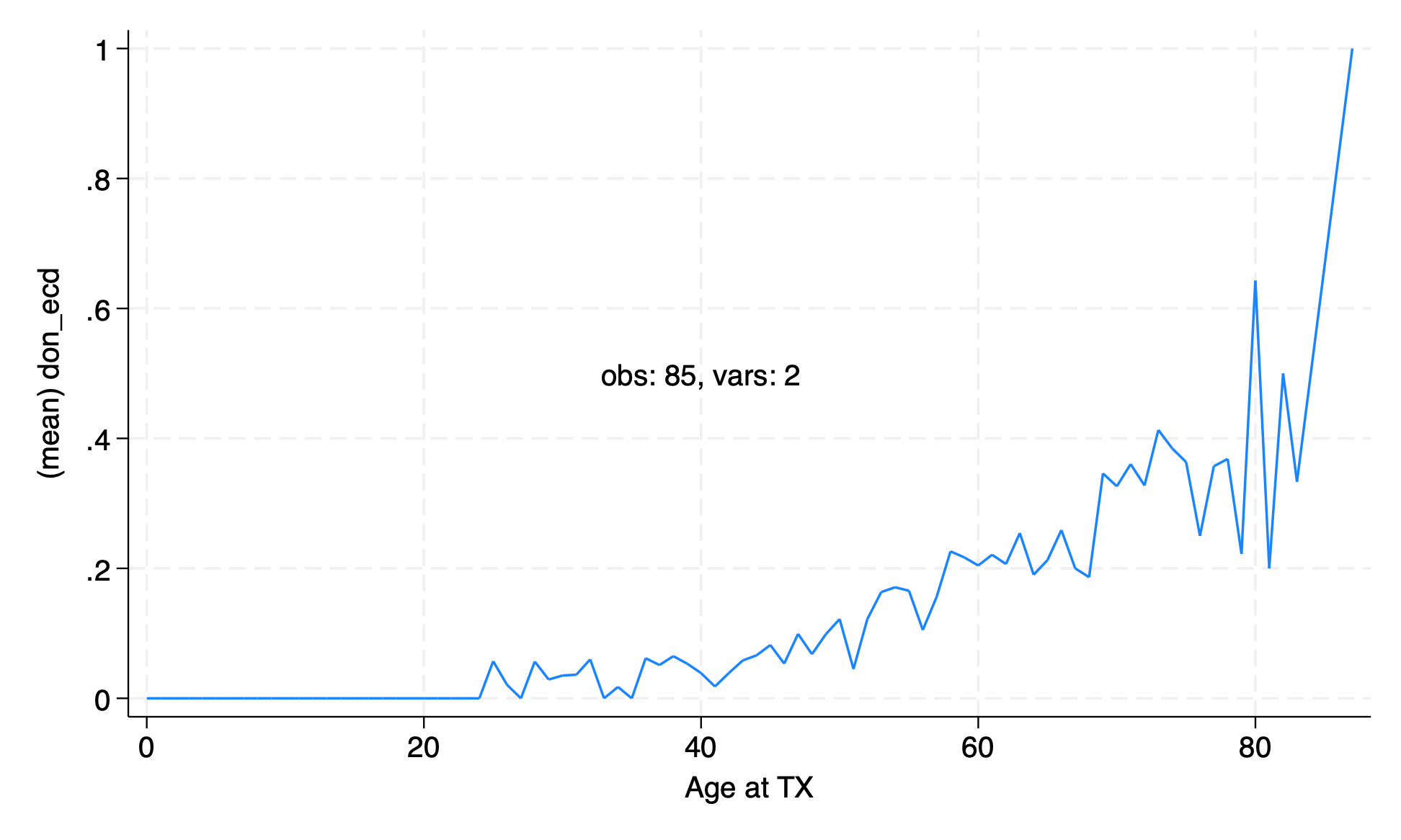
The graph of proportion of ECD transplants by age is a little messy.
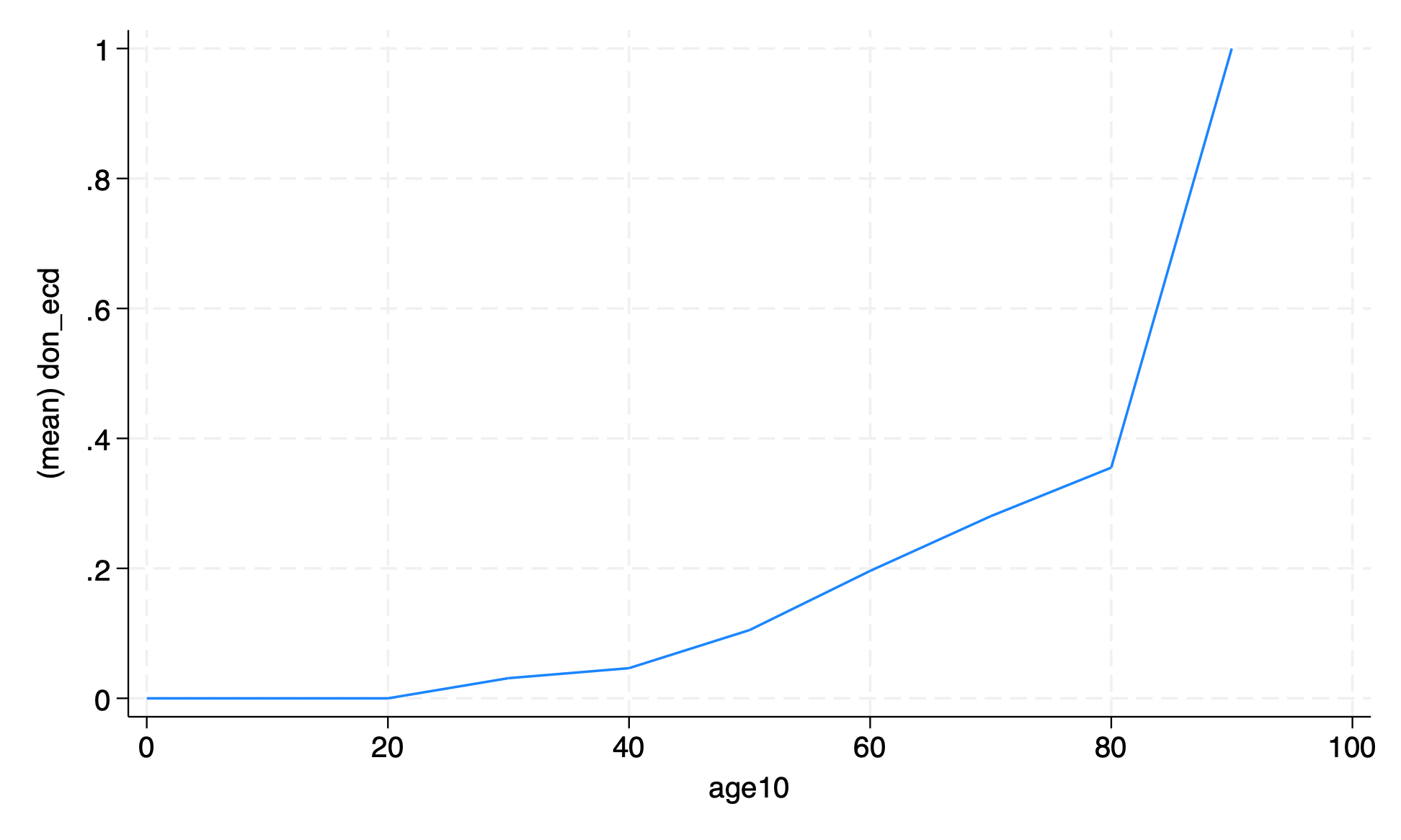
Remake the graph with the age rounded to the nearest ten years.
You have all your commands in your do file, right? Run your do file from the beginning and make sure your do file does exactly the same thing.